AlphaMaze: Enhancing Visual and Spatial Intelligence in LLMs
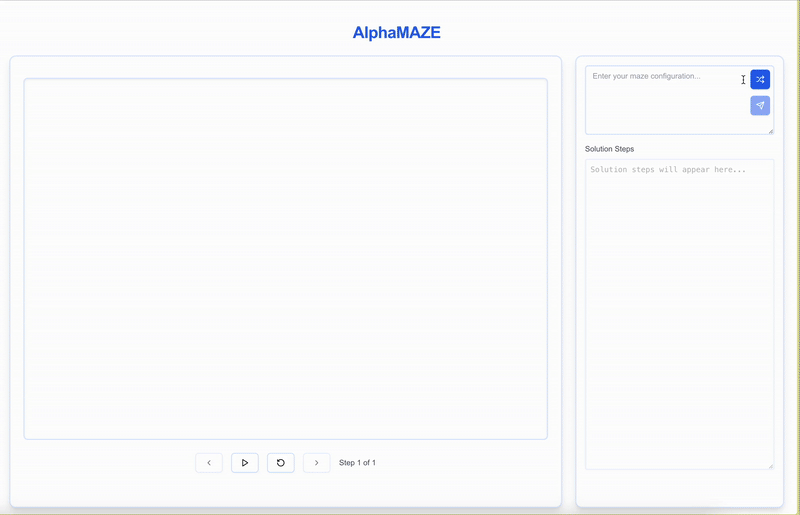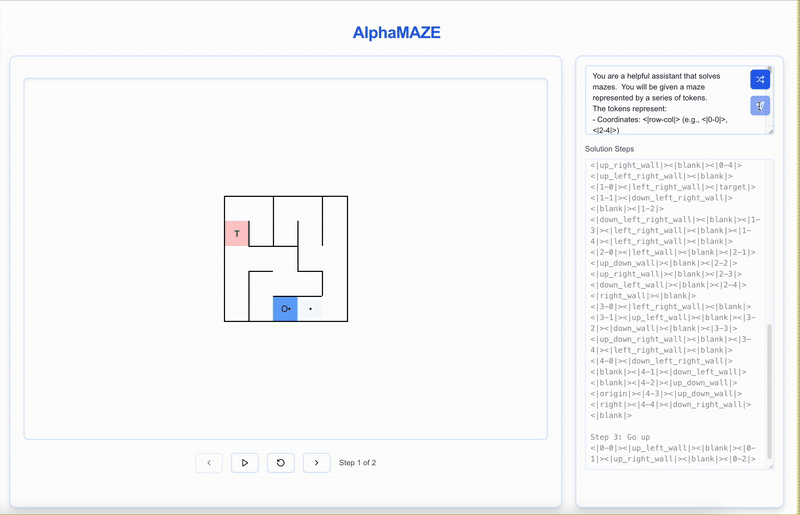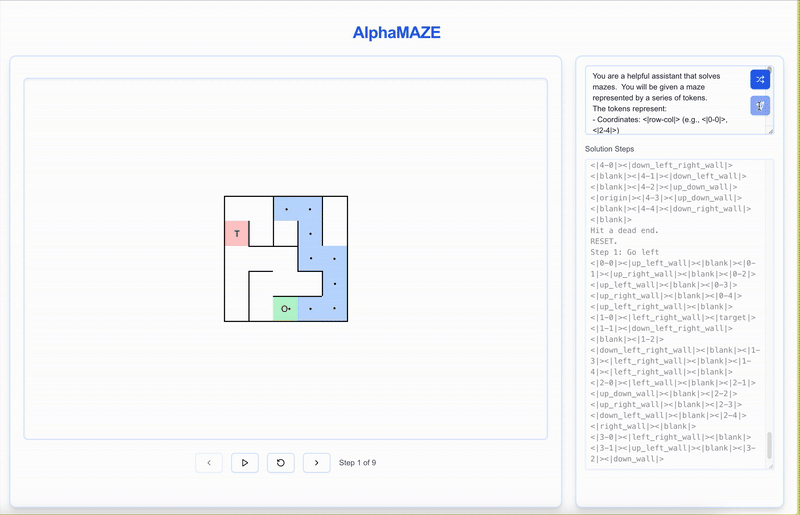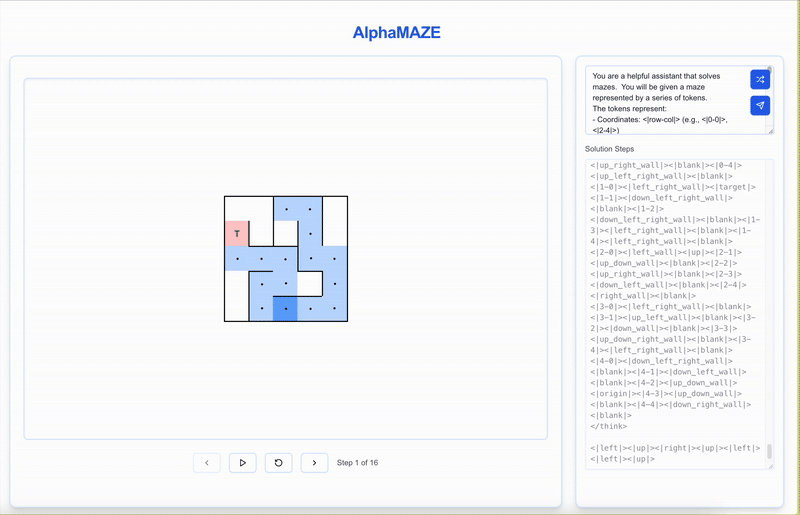 AlphaMaze is an advanced decoder-only large language model (LLM) designed to excel in visual reasoning tasks, where traditional models often fall short. It focuses on solving spatial challenges like maze navigation by using textual descriptions of mazes during training, enabling it to understand and plan spatial structures without direct visual input.
AlphaMaze is an advanced decoder-only large language model (LLM) designed to excel in visual reasoning tasks, where traditional models often fall short. It focuses on solving spatial challenges like maze navigation by using textual descriptions of mazes during training, enabling it to understand and plan spatial structures without direct visual input.
Key Features:
- Strong Visual Reasoning: AlphaMaze demonstrates impressive capabilities in handling complex visual reasoning tasks, particularly in maze-solving scenarios.
- Two-Stage Training Framework: The model uses a unique two-stage process that combines Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO) to enhance its spatial intelligence.
- Foundation Model: Built on the 1.5 billion parameter Qwen model, AlphaMaze refines its abilities through specialized training methods.
Research Contributions:
- Improved Spatial Intelligence: The research aims to boost the spatial intelligence of LLMs, allowing them to perform better on benchmarks focused on abstract reasoning.
- Innovative Techniques: By integrating GRPO, AlphaMaze shows advanced skills in navigating and understanding complex spatial environments.
Applications:
- Main building block for further research in robotics like AlphaSpace This model represents a significant advancement in teaching LLMs to think visually, bridging the gap between linguistic and spatial understanding.
Resources:
Links:
Last updated on