VoxRep: Enhancing 3D Spatial Understanding in 2D Vision-Language Models
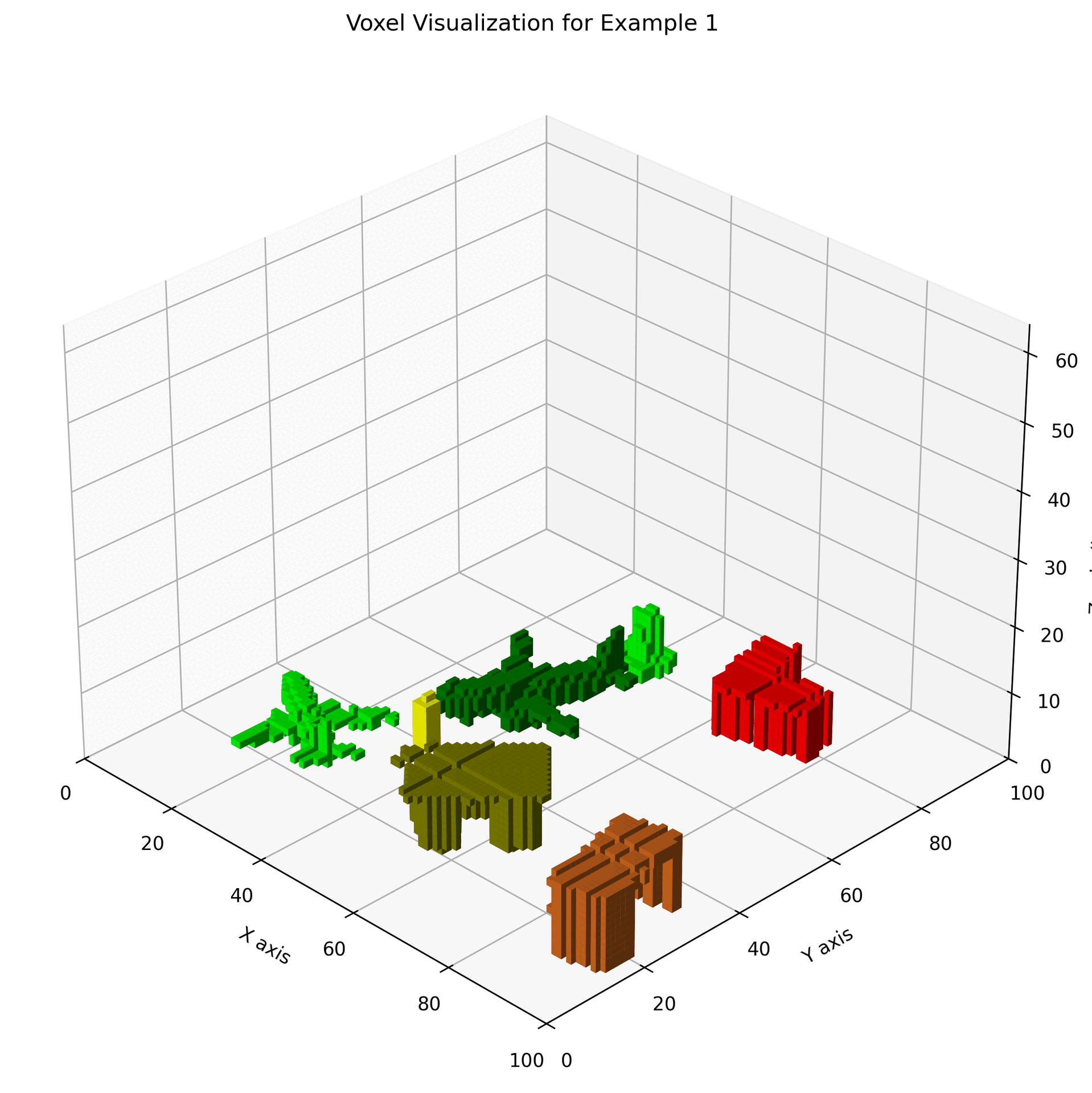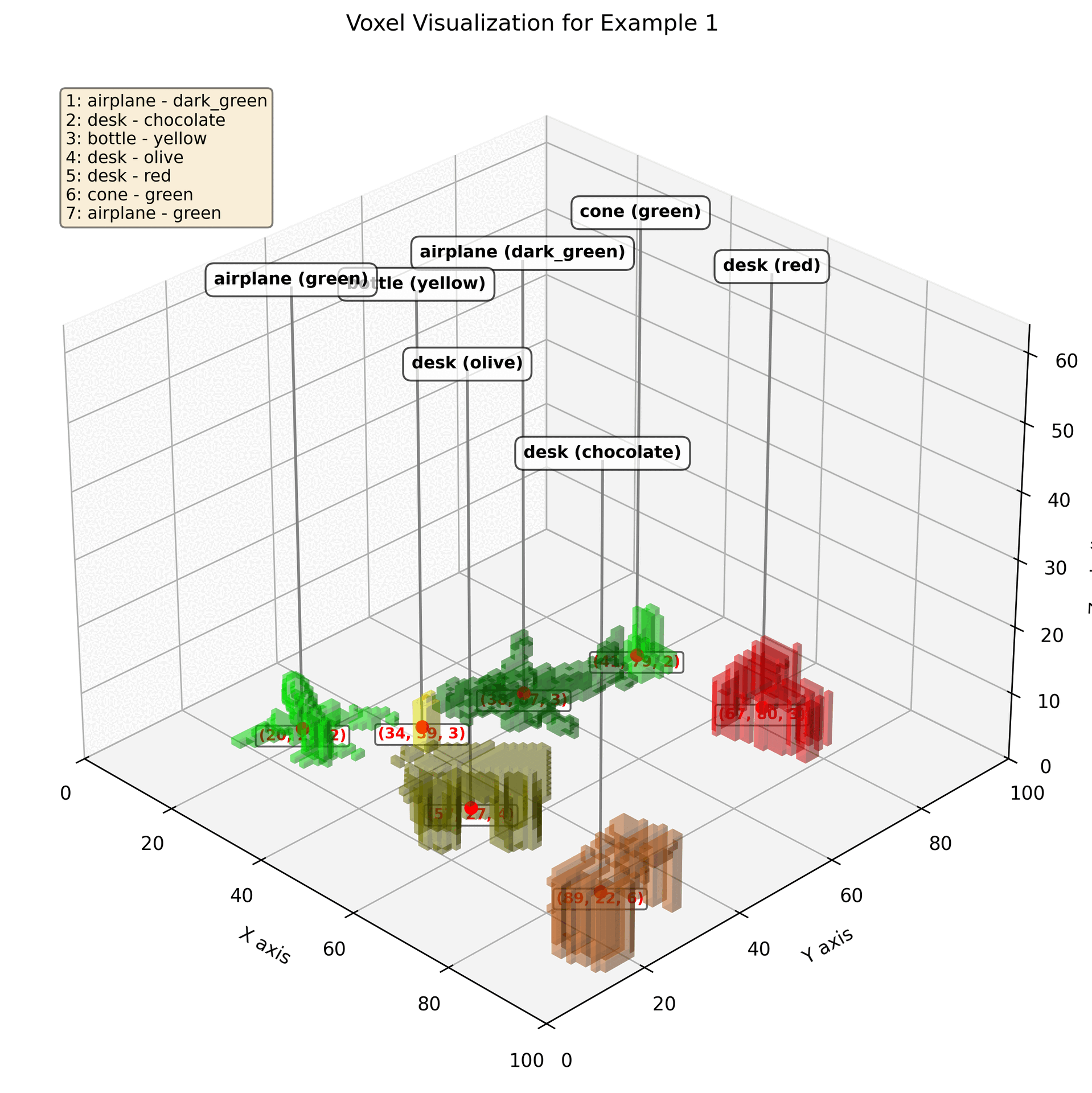
VoxRep is a novel framework designed to bridge the gap between powerful 2D Vision-Language Models (VLMs) and the challenge of 3D scene understanding directly from voxel representations. By enabling standard VLMs to interpret structured 3D voxel data, VoxRep facilitates richer spatial comprehension vital for advanced AI systems like robotics and autonomous navigation.
Key Features:
- Voxel Semantic Extraction: VoxRep empowers standard 2D VLMs to extract high-level “voxel semantics,” including object identity, color, and location, directly from voxel grids.
- Slice-Based Voxel Processing: Instead of complex 3D networks, it processes the 3D voxel space by systematically slicing it into a sequence of 2D images (akin to CT scans) which are then fed into the VLM’s image encoder.
- Leveraging Pre-trained Models: The approach effectively utilizes the power and scalability of readily available, large pre-trained 2D VLMs for 3D spatial reasoning tasks.
- Structured 3D Scene Output: The model generates interpretable, structured output (JSON format) detailing detected objects, their attributes (color, shape description), volume (voxel count), and precise 3D coordinates within the voxel space.
Research Contributions:
- 2D VLM Adaptation for 3D Voxels: Demonstrates that general-purpose 2D VLMs can effectively learn 3D voxel representations through a data adaptation strategy that flattens 3D grids into 2D slices.
- Efficient Voxel Representation Learning: Shows that learning voxel representations can be achieved efficiently at the vision-encoder level of standard VLMs, enabling structured semantic extraction.
- Scalable Voxel Understanding: Offers an efficient and scalable method for voxel-based scene understanding that bypasses the need for specialized 3D architectures or extensive 3D-specific training.
- Synthetic Data Training: Successfully trained using a dataset composed entirely of synthetically generated 3D voxel scenes, reducing the need for manual labeling.
Applications:
- Robotics: Improving 3D environmental perception and object understanding for robotic manipulation and navigation.
- Autonomous Navigation: Enhancing 3D scene comprehension for self-driving vehicles and other autonomous systems.
- 3D Asset Analysis: Enabling semantic querying and understanding of 3D models represented as voxel grids.
- Virtual/Augmented Reality: Providing richer semantic context for interactively generated or scanned 3D environments.
VoxRep represents a significant advancement in making sophisticated 3D spatial understanding more accessible by leveraging existing 2D AI models. By enabling standard VLMs to interpret voxel data, VoxRep opens new possibilities for deploying powerful foundation models in complex 3D environments.
Resources:
Last updated on